
مدلهای یادگیری ماشین به دو دسته اصلی تقسیم میشوند: یادگیری تحت نظارت (Supervised Learning) و یادگیری بدون نظارت (Unsupervised Learning). هر یک از این دستهها ویژگیها و کاربردهای خاص خود را دارند.
یادگیری ماشین (Machine Learning) یک زیرمجموعه از علم داده و هوش مصنوعی (AI) است که به سیستمها این امکان را میدهد تا بدون برنامهنویسی صریح، از دادهها یاد بگیرند و بهبود یابند. به عبارت دیگر، یادگیری ماشین تکنیکهایی را ارائه میدهد که به رایانهها اجازه میدهد از دادهها الگوها و قوانین را استخراج کرده و تصمیمات هوشمندانهتری بگیرند.
یادگیری از دادهها:
سیستمهای یادگیری ماشین از دادههای موجود برای شناسایی الگوها، روابط و روندها استفاده میکنند. این دادهها میتوانند شامل متون، تصاویر، اعداد و سایر انواع دادهها باشند.
مدلسازی:
در یادگیری ماشین، مدلها به صورت ریاضی یا آماری ایجاد میشوند که این مدلها به سیستم کمک میکنند تا پیشبینیها یا تصمیمات مبتنی بر دادههای جدید انجام دهد.
بهبود مستمر:
با دریافت دادههای جدید و در دسترس بودن تکنیکهای بهینهسازی، مدلهای یادگیری ماشین قادر به یادگیری و بهبود عملکرد خود هستند.
انواع یادگیری:
یادگیری ماشین به دو دسته اصلی تقسیم میشود:
یادگیری تحت نظارت (Supervised Learning): مدلها با استفاده از دادههای برچسبگذاریشده آموزش میبینند.
یادگیری بدون نظارت (Unsupervised Learning): مدلها با دادههای بدون برچسب آموزش میبینند و تلاش میکنند الگوها یا ساختارهای موجود را شناسایی کنند.
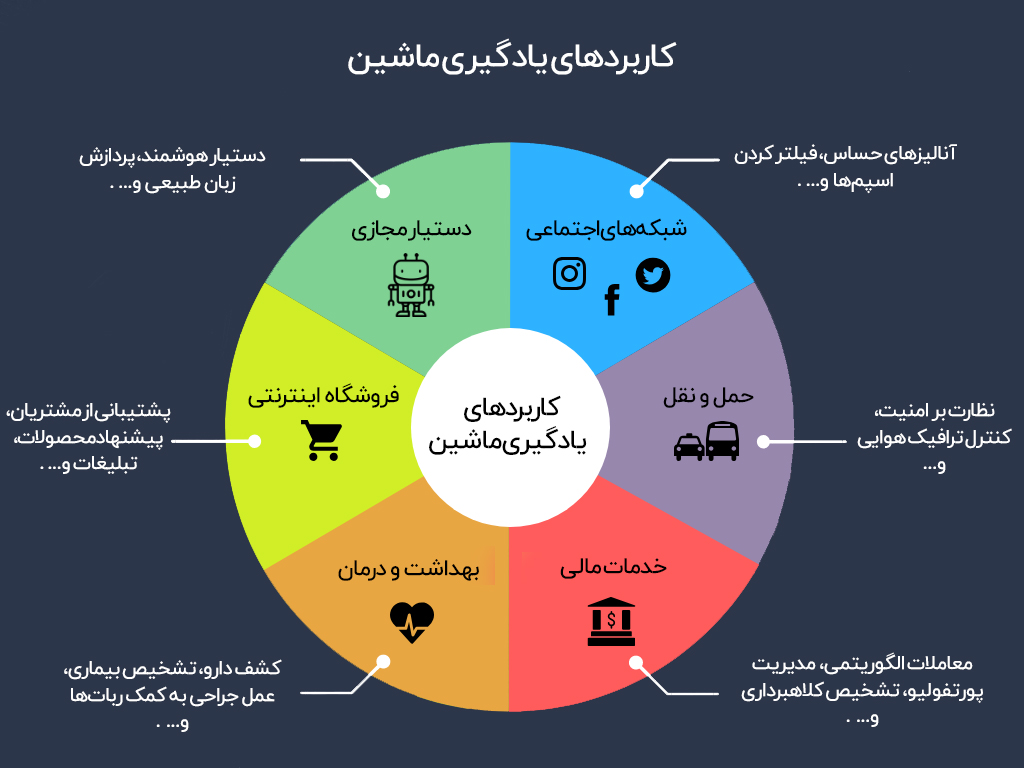
کاربردها:
یادگیری ماشین در حوزههای مختلفی کاربرد دارد، از جمله:

مدلهای یادگیری ماشین به دو دسته اصلی تقسیم میشوند: یادگیری تحت نظارت (Supervised Learning) و یادگیری بدون نظارت (Unsupervised Learning). هر کدام از این دستهها ویژگیها، روشها و کاربردهای خاص خود را دارند. در ادامه، به بررسی هر یک میپردازیم:
1. یادگیری تحت نظارت (Supervised Learning)
در یادگیری تحت نظارت، مدل با استفاده از دادههای ورودی و خروجیهای مربوطه آموزش میبیند. به عبارت دیگر، دادههای آموزشی شامل ویژگیها (متغیرهای مستقل) و برچسبها (متغیرهای وابسته) هستند. هدف این است که مدل بتواند پیشبینیهای دقیقی برای دادههای جدید بر اساس الگوهای یادگرفتهشده انجام دهد.
ویژگیها:
دادههای برچسبگذاریشده: نیاز به دادههای آموزشی با برچسبهای مشخص دارد.
مسائل پیشبینی: عمدتاً برای مسائل طبقهبندی (classification) و رگرسیون (regression) استفاده میشود.
نمونههای الگوریتمها:
کاربردها:
2. یادگیری بدون نظارت (Unsupervised Learning)
در یادگیری بدون نظارت، مدل با دادههای ورودی بدون برچسب آموزش میبیند. در اینجا، هدف شناسایی الگوها، ساختارها یا گروهبندیها در دادههاست، بدون اینکه خروجیهای مشخصی وجود داشته باشد.
ویژگیها:
دادههای بدون برچسب: نیازی به دادههای برچسبگذاریشده نیست.
شناسایی الگوها: معمولاً برای تجزیه و تحلیل خوشهای (clustering) و کاهش ابعاد (dimensionality reduction) استفاده میشود.
نمونههای الگوریتمها:
کاربردها:
یادگیری ماشین شامل طیف وسیعی از الگوریتمهاست که به دستههای مختلفی تقسیم میشوند. در زیر، انواع اصلی الگوریتمهای یادگیری ماشین و توضیحات مربوط به هر کدام آورده شده است:
1. یادگیری تحت نظارت (Supervised Learning)
در این نوع یادگیری، الگوریتم با استفاده از دادههای ورودی و خروجیهای مشخص آموزش میبیند. هدف پیشبینی خروجیها برای دادههای جدید است.
الف) الگوریتمهای رگرسیون
رگرسیون خطی (Linear Regression): برای پیشبینی مقادیر عددی بر اساس یک یا چند ویژگی.
رگرسیون لجستیک (Logistic Regression): برای پیشبینی احتمال وقوع یک رویداد (بیشتر در مسائل طبقهبندی).
ب) الگوریتمهای طبقهبندی
درخت تصمیم (Decision Tree): ساختار درختی برای طبقهبندی دادهها.
ماشینهای بردار پشتیبان (Support Vector Machines - SVM): جداسازی دادهها با استفاده از یک مرز (hyperplane).
کلاسبندی نزدیکترین همسایه (K-Nearest Neighbors - KNN): تخصیص طبقه به یک نمونه جدید بر اساس طبقه نزدیکترین همسایهها.
شبکههای عصبی (Neural Networks): الگوریتمهای پیچیده برای شناسایی الگوهای غیرخطی.
2. یادگیری بدون نظارت (Unsupervised Learning)
در این نوع یادگیری، الگوریتم با استفاده از دادههای ورودی بدون برچسب آموزش میبیند و هدف شناسایی الگوها یا ساختارهای موجود در دادههاست.
الف) الگوریتمهای خوشهبندی
خوشهبندی k-means: تقسیم دادهها به k خوشه بر اساس میانگین.
خوشهبندی هیرارشی (Hierarchical Clustering): ایجاد درختی از خوشهها برای شناسایی ساختارها.
DBSCAN: خوشهبندی بر اساس چگالی دادهها.
ب) الگوریتمهای کاهش ابعاد
تحلیل مؤلفههای اصلی (Principal Component Analysis - PCA): کاهش ابعاد دادهها با حفظ ویژگیهای مهم.
t-SNE: روش کاهش ابعاد برای نمایش دادهها در فضای دو یا سهبعدی بهصورت بصری.
3. یادگیری تقویتی (Reinforcement Learning)
در این نوع یادگیری، الگوریتم با استفاده از تجربیات و بازخوردها از محیط خود یاد میگیرد. هدف یادگیری سیاستی است که بهترین اقدام را در شرایط مختلف انتخاب کند.
Q-learning: یادگیری ارزش اقدامات برای انتخاب بهترین سیاست.
Deep Q-Networks (DQN): ترکیب یادگیری تقویتی با شبکههای عصبی عمیق.
Policy Gradient Methods: بهطور مستقیم سیاست را بهینه میکند.
4. یادگیری نیمهنظارت (Semi-Supervised Learning)
ترکیبی از یادگیری تحت نظارت و بدون نظارت است. در اینجا، الگوریتم از دادههای برچسبگذاریشده و بدون برچسب استفاده میکند تا دقت پیشبینی را افزایش دهد.
5. یادگیری چندوظیفهای (Multi-task Learning)
مدلها به گونهای طراحی میشوند که بتوانند به طور همزمان چندین وظیفه را یاد بگیرند، بهویژه زمانی که دادهها بین وظایف مشترک باشند.
خدمات اس دیتا در زمینه مدلهای یادگیری ماشین تحت نظارت و بدون نظارت شامل طیف گستردهای از مشاوره، پیادهسازی، و پشتیبانی است که به کسبوکارها کمک میکند تا از قدرت یادگیری ماشین بهرهبرداری کنند. در ادامه به تشریح خدمات مختلف این شرکت در هر دو دسته یادگیری ماشین میپردازیم:
1. خدمات یادگیری تحت نظارت (Supervised Learning)
الف) مشاوره و تحلیل نیازها
شناسایی اهداف تجاری: مشاوره برای تعیین نیازهای خاص کسبوکار و تعریف اهداف دقیق پروژه.
تحلیل دادهها: بررسی و تحلیل دادههای موجود برای شناسایی مناسبترین الگوریتم و متغیرهای کلیدی.
ب) طراحی و پیادهسازی مدل
انتخاب الگوریتم: انتخاب بهترین الگوریتمهای رگرسیون و طبقهبندی (مانند رگرسیون خطی، درخت تصمیم، و شبکههای عصبی) متناسب با دادهها و اهداف.
مدلسازی و آموزش: پیادهسازی مدلها و آموزش آنها با استفاده از دادههای برچسبگذاریشده.
تنظیم و بهینهسازی: بهینهسازی مدلها با استفاده از تکنیکهای مختلف مانند جستجوی شبکهای (Grid Search) و اعتبارسنجی متقابل (Cross-Validation).
ج) تحلیل و ارزیابی نتایج
تحلیل نتایج: بررسی نتایج پیشبینیها و ارزیابی دقت مدلها.
گزارشدهی: تهیه گزارشهای جامع و بصری برای ارائه به ذینفعان.
2. خدمات یادگیری بدون نظارت (Unsupervised Learning)
الف) مشاوره و تحلیل داده
شناسایی الگوها: مشاوره برای شناسایی و استخراج الگوها و روندها از دادههای بدون برچسب.
تحلیل خوشهبندی: تحلیل و شناسایی خوشهها در دادهها برای گروهبندی مشتریان یا محصولات.
ب) طراحی و پیادهسازی مدل
انتخاب الگوریتم: انتخاب بهترین الگوریتمهای خوشهبندی (مانند k-means و DBSCAN) و کاهش ابعاد (مانند PCA).
مدلسازی و آموزش: پیادهسازی و آموزش مدلهای بدون نظارت برای شناسایی ساختارهای موجود در دادهها.
ج) تحلیل و گزارشدهی
تحلیل نتایج: بررسی و تحلیل نتایج خوشهبندی و کاهش ابعاد.
گزارشدهی: تهیه گزارشهای جامع درباره الگوهای شناساییشده و ارائه توصیههای عملی.
3. خدمات مشترک برای هر دو نوع یادگیری
الف) آموزش و توانمندسازی
آموزش در زمینه یادگیری ماشین: ارائه کارگاهها و دورههای آموزشی برای تیمهای داخلی کسبوکارها به منظور آشنایی با تکنیکهای یادگیری ماشین و نحوه پیادهسازی آنها.
آموزش ابزارها: آموزش استفاده از ابزارها و نرمافزارهای مرتبط مانند Python، R و ابزارهای BI.
ب) یکپارچهسازی و استقرار
یکپارچهسازی مدلها: ادغام مدلهای یادگیری ماشین با سیستمهای موجود در کسبوکار برای بهینهسازی عملکرد.
استقرار مدلها: پیادهسازی مدلها در محیطهای تولید برای استفاده در زمان واقعی.
ج) نگهداری و بهروزرسانی مدلها
نظارت بر عملکرد: پایش و نظارت بر عملکرد مدلها و بهروزرسانی آنها در صورت نیاز.
تست و ارزیابی دورهای: انجام ارزیابیهای دورهای برای اطمینان از دقت و کارایی مدلها.