
آمار بهعنوان یکی از ابزارهای کلیدی در ارزیابی الگوریتمهای پردازش زبان طبیعی، امکان تحلیل دقیق عملکرد مدلها را فراهم میکند. با استفاده از ابزارهای آماری، میتوان معیارهایی مانند دقت، یادآوری و صحت پیشبینی را محاسبه کرد و به بهبود الگوریتمها پرداخت. تحلیل توزیع دادهها، شناسایی ناهنجاریها و ارزیابی خروجی مدلها از دیگر کاربردهای آمار در این حوزه است.
برای مثال، در یک مدل تحلیل احساسات با 10,000 داده، استفاده از تحلیلهای آماری نشان داد که 85 درصد پیشبینیها با دادههای واقعی همخوانی دارد. این ترکیب، الگوریتمهای پردازش زبان طبیعی را دقیقتر، قابلاعتمادتر و کارآمدتر میکند.
هوش مصنوعی در آمار با ترکیب این دو حوزه، ابزارهایی پیشرفته برای مدیریت زبان و تحلیل متن ارائه میدهد.
چگونه تحلیل آماری به ارزیابی مدلهای پردازش زبان طبیعی کمک میکند؟
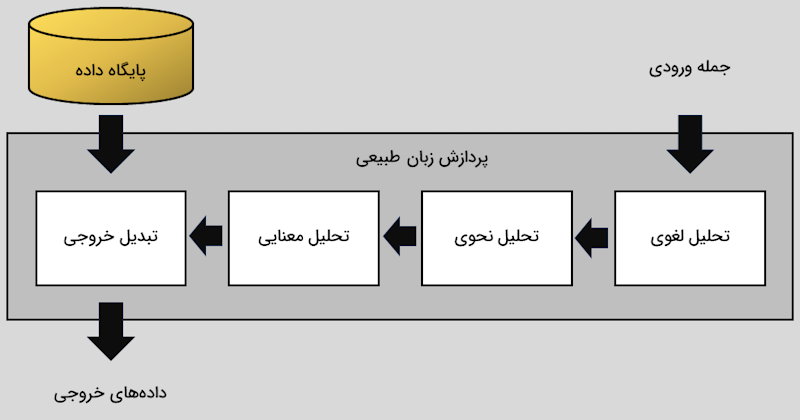
تحلیل آماری یکی از ابزارهای اساسی برای ارزیابی عملکرد مدلهای پردازش زبان طبیعی (NLP) است. این ابزارها با بررسی دقت، صحت، یادآوری، و معیارهای مختلف، نقاط قوت و ضعف مدلها را شناسایی میکنند. از جمله کاربردهای تحلیل آماری در این حوزه میتوان به تحلیل توزیع دادهها، ارزیابی نتایج مدل، و مدیریت دادههای نامتوازن اشاره کرد. این روشها به بهبود دقت و کارایی مدلهای NLP کمک میکنند. در ادامه، به توضیح این موضوع همراه با مثالهای عملی و تحلیلهای عددی پرداخته میشود.
1. تحلیل معیارهای ارزیابی عملکرد مدل
آمار به محاسبه و تفسیر معیارهایی مانند دقت (Accuracy)، یادآوری (Recall) و صحت (Precision) کمک میکند. این معیارها نشان میدهند که مدل NLP چقدر توانسته است دادههای ورودی را بهدرستی پردازش کند.
مثال:
در یک مدل تحلیل احساسات:
- دادهها شامل 10,000 نظر کاربران هستند.
- مدل 8,500 مورد را بهدرستی پیشبینی کرده است.
- دقت مدل (Accuracy) برابر با 85 درصد است.
تحلیل آماری نشان میدهد که مدل در طبقهبندی دادههای مثبت دقت بالایی دارد اما در طبقهبندی دادههای خنثی عملکرد ضعیفتری دارد.
2. تحلیل دادههای نامتوازن
در بسیاری از مسائل NLP، دادهها نامتوازن هستند؛ به این معنا که برخی دستهها (مانند نظرات مثبت) نسبت به دیگر دستهها تعداد بیشتری دارند. تحلیل آماری به مدیریت این عدم توازن کمک میکند.
مثال:
در یک مدل تشخیص اسپم ایمیل:
- 90 درصد دادهها به ایمیلهای عادی و 10 درصد به اسپم تعلق دارند.
- مدل بدون مدیریت نامتوازنی دادهها، 95 درصد دقت دارد، اما تنها 50 درصد از اسپمها را بهدرستی شناسایی میکند.
تحلیل آماری با نمونهبرداری مجدد یا وزندهی دادههای کمیاب، مدل را بهبود میدهد:
- دقت شناسایی اسپم پس از اعمال تغییرات: 85 درصد
3. تحلیل توزیع دادهها
آمار میتواند توزیع دادهها را بررسی کند و به شناسایی دادههای ناهنجار یا رفتارهای غیرمعمول در دادههای ورودی کمک کند.
مثال:
در یک سیستم خلاصهسازی متن:
- میانگین طول اسناد ورودی 500 کلمه است.
- تحلیل آماری نشان میدهد که برخی اسناد دارای طول بیش از 1,500 کلمه هستند.
مدیریت این دادههای ناهنجار باعث بهبود عملکرد مدل در خلاصهسازی اسناد کوتاه و بلند میشود.
4. ارزیابی کیفیت خروجی مدل
تحلیل آماری میتواند خروجیهای مدل NLP را با معیارهایی مانند BLEU یا ROUGE بررسی کند. این معیارها کیفیت پیشبینیهای مدل را ارزیابی میکنند.
مثال:
در یک مدل ترجمه ماشینی:
- ترجمههای مدل با ترجمه انسانی مقایسه شدهاند.
- BLEU مدل برابر با 0.7 است که نشاندهنده کیفیت بالای ترجمه است.
تحلیل آماری نشان میدهد که مدل در ترجمه جملات کوتاهتر بهتر عمل میکند اما در جملات طولانیتر دچار خطا میشود.
5. شناسایی و تحلیل دادههای پرت
دادههای پرت میتوانند باعث کاهش دقت مدل شوند. ابزارهای آماری به شناسایی و حذف این دادهها کمک میکنند.
مثال:
در یک مدل شناسایی موجودیتهای نامدار (NER):
- 5 درصد از دادهها حاوی برچسبهای اشتباه هستند.
- حذف این دادههای پرت باعث افزایش دقت مدل از 78 درصد به 85 درصد میشود.
6. ارزیابی عملکرد با تحلیل سریهای زمانی
در مسائل NLP پویا، مانند تحلیل جریانهای اجتماعی یا دادههای زنده، تحلیل سریهای زمانی میتواند عملکرد مدل را بهبود دهد.
مثال:
در پیشبینی موضوعات داغ در رسانههای اجتماعی:
- دادههای روزانه شامل 10,000 پست است.
- تحلیل آماری نشان میدهد که بیشترین فعالیت در ساعات خاصی رخ میدهد.
مدل با استفاده از این تحلیل میتواند پیشبینیهای دقیقتری از موضوعات داغ ارائه دهد.
7. تحلیل همبستگی برای شناسایی ویژگیهای کلیدی
تحلیل همبستگی میتواند نشان دهد که کدام ویژگیها بیشترین تأثیر را در پیشبینی مدل دارند.
مثال:
در یک مدل طبقهبندی متن:
- تحلیل همبستگی نشان میدهد که وجود برخی کلمات خاص مانند "تخفیف" یا "رایگان" با دستهبندی بهعنوان اسپم همبستگی قوی دارد.
مدل با استفاده از این اطلاعات میتواند پیشبینی دقیقتری ارائه دهد.
بهترین ابزارهای آماری برای تحلیل خروجیهای مدلهای پردازش زبان طبیعی
تحلیل خروجیهای مدلهای پردازش زبان طبیعی (NLP) به ابزارهایی نیاز دارد که بتوانند دقت، صحت، و کیفیت پیشبینیها را بررسی کنند. ابزارهای آماری در این زمینه نقش حیاتی ایفا میکنند، زیرا با ارزیابی عملکرد مدل و تحلیل دادهها، به بهبود کارایی سیستمهای NLP کمک میکنند. در ادامه، مهمترین ابزارهای آماری برای تحلیل خروجیهای NLP همراه با کاربردهای عملی بررسی میشوند.
1. معیار BLEU (Bilingual Evaluation Understudy)
BLEU یکی از پرکاربردترین ابزارها برای ارزیابی مدلهای ترجمه ماشینی است. این معیار به بررسی میزان شباهت ترجمههای مدل با ترجمه انسانی میپردازد.
کاربرد:
- ارزیابی کیفیت خروجیهای ترجمه ماشینی
- تحلیل ترجمه متنهای کوتاه و بلند
مثال:
در تحلیل ترجمه یک متن:
- مدل یک جمله انگلیسی را با نمره BLEU برابر با 0.8 ترجمه کرده است، که نشاندهنده شباهت 80 درصدی با ترجمه انسانی است.
2. معیار ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
ROUGE برای ارزیابی مدلهای خلاصهسازی متن استفاده میشود و تمرکز آن بر مقایسه کلمات یا جملات مشترک بین خلاصه تولید شده و خلاصه مرجع است.
کاربرد:
- ارزیابی کیفیت خلاصههای متنی
- شناسایی کارایی مدل در بازیابی اطلاعات کلیدی
مثال:
در ارزیابی خلاصه یک مقاله:
- مدل خلاصهای با امتیاز ROUGE-1 برابر با 0.7 تولید کرده است، که نشاندهنده 70 درصد تطابق کلمات کلیدی با خلاصه مرجع است.
3. تحلیل پراکندگی (Dispersion Analysis)
این ابزار به بررسی توزیع کلمات، عبارات یا ویژگیهای زبانی در خروجیهای مدل میپردازد و به شناسایی ناهماهنگیها کمک میکند.
کاربرد:
- شناسایی کلمات تکراری در ترجمه یا خلاصه
- تحلیل تعادل در استفاده از کلمات کلیدی
مثال:
در خروجی یک مدل ترجمه:
- تحلیل پراکندگی نشان میدهد که کلمه "تخفیف" بیش از 10 بار در یک پاراگراف تکرار شده است، که نشاندهنده ناهماهنگی در خروجی است.
4. تحلیل سریهای زمانی
این ابزار در مسائل پویا، مانند تحلیل دادههای زنده یا جریانهای رسانههای اجتماعی، به ارزیابی کیفیت و تغییرات خروجی مدل کمک میکند.
کاربرد:
- ارزیابی مدلهای پیشبینی موضوعات داغ
- تحلیل تغییرات زبانی در دادههای زنده
مثال:
در تحلیل موضوعات داغ روزانه در رسانههای اجتماعی:
- دادهها نشان میدهند که مدل توانسته است با دقت 85 درصد تغییرات موضوعی را پیشبینی کند.
5. معیار F1-Score
F1-Score یک ابزار استاندارد برای ارزیابی مدلهای طبقهبندی متن است که توازن بین صحت (Precision) و یادآوری (Recall) را بررسی میکند.
کاربرد:
- ارزیابی مدلهای دستهبندی متن (مثلاً تشخیص احساسات یا اسپم)
- تحلیل عملکرد مدل در دادههای نامتوازن
مثال:
در یک مدل تحلیل احساسات:
- دقت: 90 درصد
- یادآوری: 85 درصد
- F1-Score مدل: 87.5 درصد
6. تحلیل همبستگی
تحلیل همبستگی به شناسایی روابط بین متغیرها کمک میکند و میتواند ویژگیهای تأثیرگذار در خروجیهای مدل را شناسایی کند.
کاربرد:
- تحلیل تأثیر ویژگیها بر عملکرد مدل
- شناسایی روابط غیرمنتظره در دادهها
مثال:
در تحلیل احساسات متن:
- همبستگی بالایی بین استفاده از کلمات منفی و پیشبینی احساس منفی وجود دارد.
7. معیار Perplexity
Perplexity برای ارزیابی مدلهای زبانی (Language Models) استفاده میشود و نشاندهنده توانایی مدل در پیشبینی کلمات بعدی است.
کاربرد:
- ارزیابی کیفیت مدلهای تولید متن
- تحلیل تطابق مدل با دادههای آموزشی
مثال:
یک مدل زبانی با Perplexity برابر با 15 نشاندهنده عملکرد بهتری نسبت به مدلی با Perplexity برابر با 50 است.
8. آزمونهای فرضیه
آزمونهای فرضیه برای ارزیابی تفاوت بین عملکرد مدلها یا تأثیر متغیرهای مختلف بر خروجیها استفاده میشوند.
کاربرد:
- مقایسه عملکرد مدلهای مختلف NLP
- تحلیل تأثیر ویژگیهای خاص بر پیشبینیها
مثال:
در ارزیابی دو مدل ترجمه ماشینی:
- مدل A با BLEU برابر با 0.6
- مدل B با BLEU برابر با 0.8
آزمون فرضیه نشان میدهد که تفاوت عملکرد این دو مدل از نظر آماری معنیدار است.
9. تحلیل دادههای پرت
شناسایی دادههای پرت یکی از ابزارهای مهم برای بهبود کیفیت خروجیهای مدل است. این دادهها میتوانند نشاندهنده ناهنجاریها یا خطاهای مدل باشند.
کاربرد:
- شناسایی خروجیهای غیرمنطقی یا ناهماهنگ
- بهبود کیفیت کلی مدل
مثال:
در یک مدل خلاصهسازی متن:
- تحلیل نشان میدهد که در یک خلاصه، اطلاعات نامرتبطی گنجانده شده است که بهعنوان داده پرت شناسایی میشود.
10. تحلیل تنوع خروجیها
این ابزار به ارزیابی تنوع و غنای زبانی در خروجیهای مدل کمک میکند و به شناسایی تکرارهای غیرضروری کمک میکند.
کاربرد:
- ارزیابی مدلهای تولید متن
- تحلیل کیفیت زبان در خروجیها
مثال:
در یک مدل تولید داستان کوتاه:
- تحلیل آماری نشان میدهد که مدل از یک الگوی ثابت برای ساخت جملات استفاده میکند، که منجر به کاهش کیفیت داستان شده است.
نتیجهگیری
تحلیل آماری ابزارهای قدرتمندی برای ارزیابی عملکرد مدلهای پردازش زبان طبیعی ارائه میدهد. این ابزارها با تحلیل دادهها، مدیریت ناهنجاریها و ارائه معیارهای دقیق ارزیابی، به بهبود دقت و کارایی مدلها کمک میکنند. ترکیب این تحلیلها با یادگیری ماشین نشان میدهد که چگونه هوش مصنوعی در آمار میتواند سیستمهای NLP را هوشمندتر و کارآمدتر کند.



