مدلهای رگرسیون و طبقهبندی دو تکنیک اصلی در یادگیری ماشین هستند که برای پیشبینیها و تحلیل دادهها استفاده میشوند. این مدلها به سازمانها و محققان کمک میکنند تا الگوها و روابط موجود در دادهها را شناسایی کنند و از آنها برای تصمیمگیریهای هوشمند بهرهبرداری کنند.
مدل های رگرسیون و طبقه بندی برای پیشبینیها
مدلهای رگرسیون و طبقهبندی از ابزارهای اساسی در یادگیری ماشین و تحلیل دادهها هستند که برای پیشبینیهای مختلف به کار میروند. هر یک از این مدلها ویژگیها و کاربردهای خاص خود را دارند. در ادامه به بررسی این مدلها و چگونگی استفاده از آنها برای پیشبینیها میپردازیم.
1. مدلهای رگرسیون
مدلهای رگرسیون به پیشبینی مقادیر عددی (مقدار پیوسته) میپردازند. این مدلها برای تعیین روابط بین یک متغیر وابسته و یک یا چند متغیر مستقل طراحی شدهاند.
انواع مدلهای رگرسیون:
رگرسیون خطی:
رگرسیون خطی ساده: برای پیشبینی مقدار یک متغیر وابسته بر اساس یک متغیر مستقل.
رگرسیون خطی چندگانه: برای پیشبینی مقدار یک متغیر وابسته بر اساس چندین متغیر مستقل.
رگرسیون لجستیک:
برای پیشبینی احتمال وقوع یک رویداد باینری (مانند بله/خیر) استفاده میشود. این مدل به نوعی رگرسیون به حساب میآید، اما خروجی آن یک احتمال است.
رگرسیون پلینومیک:
برای مدلسازی روابط غیرخطی بین متغیرها استفاده میشود. این مدل میتواند از توابع چندجملهای برای پیشبینی استفاده کند.
کاربردهای رگرسیون:
- پیشبینی قیمت مسکن با توجه به ویژگیهای آن (مساحت، تعداد اتاق، موقعیت جغرافیایی و ...).
- پیشبینی میزان فروش بر اساس عوامل مختلف بازاریابی.
- پیشبینی روندهای اقتصادی و مالی.
2. مدلهای طبقهبندی
مدلهای طبقهبندی برای پیشبینی کلاس یا دسته یک متغیر وابسته (خروجی) بر اساس ویژگیهای آن (ورودی) به کار میروند. این مدلها برای حل مسائل با خروجی دستهای (باینری یا چندکلاسه) استفاده میشوند.
انواع مدلهای طبقهبندی:
درخت تصمیم:
یک مدل بصری که دادهها را با تقسیم بر اساس ویژگیها به دستههای مختلف تقسیم میکند.
SVM (Support Vector Machine):
از الگوریتمهای قدرتمند برای تعیین مرز تصمیمگیری و دستهبندی دادهها استفاده میکند.
شامل چندین لایه از نورونها که برای شناسایی الگوهای پیچیده در دادهها طراحی شدهاند. این مدلها بهخصوص در یادگیری عمیق (Deep Learning) محبوب هستند.
کلاسبندیکنندههای k-نزدیکترین همسایه (k-NN):
دادهها را بر اساس نزدیکترین همسایهها به یک نقطه جدید دستهبندی میکند.
کاربردهای طبقهبندی:
- تشخیص تقلب در تراکنشهای مالی.
- تشخیص بیماریها بر اساس دادههای پزشکی.
- دستهبندی ایمیلها به اسپم یا غیر اسپم.
3. تفاوتهای کلیدی بین رگرسیون و طبقهبندی
نوع خروجی: رگرسیون خروجی عددی (مقدار پیوسته) تولید میکند، در حالی که طبقهبندی خروجی دستهای (کلاس) تولید میکند.
هدف مدل: هدف رگرسیون تخمین مقدار متغیر وابسته است، در حالی که هدف طبقهبندی تعیین دسته متغیر وابسته است.
معیارهای ارزیابی: عملکرد رگرسیون معمولاً با معیارهایی مانند MSE (میانگین مربع خطا) یا R² ارزیابی میشود، در حالی که طبقهبندی با معیارهایی مانند دقت (Accuracy)، دقت متوسط (F1-Score) و منحنی ROC ارزیابی میشود.
4. فرآیند ساخت مدلهای رگرسیون و طبقهبندی
- جمعآوری داده: جمعآوری و آمادهسازی دادههای مورد نیاز برای مدلسازی.
- پیشپردازش داده: شامل پاکسازی دادهها، تبدیل ویژگیها و انتخاب ویژگیهای مهم.
- تقسیم داده: تقسیم دادهها به مجموعههای آموزشی و آزمایشی.
- ساخت مدل: انتخاب الگوریتم مناسب و آموزش مدل با استفاده از دادههای آموزشی.
- ارزیابی مدل: استفاده از دادههای آزمایشی برای ارزیابی عملکرد مدل و انجام تنظیمات لازم.
- استفاده از مدل: استفاده از مدل برای پیشبینیهای جدید و تحلیل دادهها.
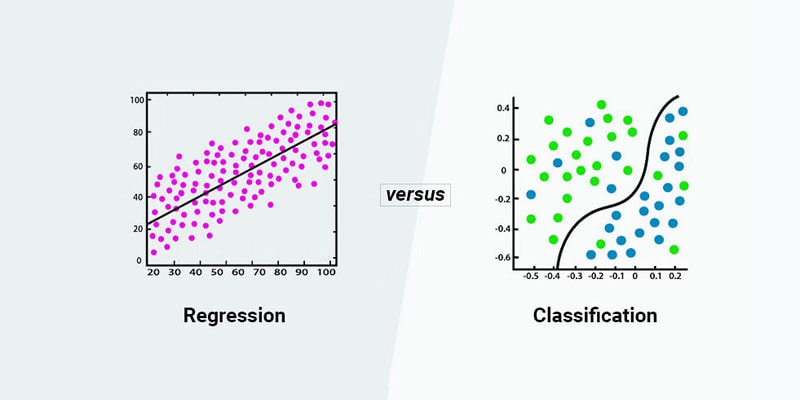
تفاوت الگوریتم های رگرسیون و طبقه بندی
الگوریتمهای رگرسیون و طبقهبندی هر دو جزو تکنیکهای یادگیری ماشین هستند و برای پیشبینی و تحلیل دادهها به کار میروند. با این حال، آنها در برخی جنبهها تفاوتهای اساسی دارند. در ادامه به بررسی این تفاوتها میپردازیم.
1. نوع خروجی
رگرسیون: خروجی مدلهای رگرسیون عددی و پیوسته است. به عبارت دیگر، این مدلها برای پیشبینی مقادیر عددی استفاده میشوند. به عنوان مثال، پیشبینی قیمت یک خانه یا دما در یک روز خاص.
طبقهبندی: خروجی مدلهای طبقهبندی دستهای و غیر پیوسته است. این مدلها برای پیشبینی کلاس یا دسته یک متغیر وابسته به کار میروند. به عنوان مثال، تشخیص اینکه آیا یک ایمیل اسپم است یا خیر (باینری) یا دستهبندی یک تصویر به یک گروه خاص (چندکلاسه).
2. هدف مدل
رگرسیون: هدف اصلی در مدلهای رگرسیون یافتن رابطه بین متغیر وابسته و یک یا چند متغیر مستقل و پیشبینی مقادیر جدید است.
طبقهبندی: هدف اصلی در مدلهای طبقهبندی تعیین کلاس یا دسته یک ورودی بر اساس ویژگیهای آن است.
3. معیارهای ارزیابی
رگرسیون: برای ارزیابی عملکرد مدلهای رگرسیون از معیارهایی مانند:
- میانگین خطای مطلق (MAE): میانگین مطلق خطاها.
- میانگین مربعات خطا (MSE): میانگین مربع خطاها.
- R²: نشاندهنده قدرت توضیحدهی مدل است.
- طبقهبندی: برای ارزیابی عملکرد مدلهای طبقهبندی از معیارهایی مانند:
- دقت (Accuracy): نسبت پیشبینیهای صحیح به کل پیشبینیها.
- F1-Score: ترکیبی از دقت و یادآوری.
- منحنی ROC و AUC: اندازهگیری عملکرد مدل در دقت و قابلیت تشخیص.
4. الگوریتمها
الگوریتمهای رگرسیون:
- رگرسیون خطی
- رگرسیون چندگانه
- رگرسیون لجستیک (هرچند که بیشتر به طبقهبندی نسبت داده میشود، اما برای پیشبینی احتمال استفاده میشود)
- رگرسیون پلینومیک
الگوریتمهای طبقهبندی:
- درخت تصمیم
- SVM (Support Vector Machine)
- شبکههای عصبی
- k-نزدیکترین همسایه (k-NN)
5. نحوه کار با دادهها
رگرسیون: در رگرسیون، روابط خطی یا غیرخطی بین متغیرها بررسی میشود و مدل سعی در برقراری یک تابع ریاضی برای تخمین خروجی دارد.
طبقهبندی: در طبقهبندی، مدل با یادگیری از نمونههای موجود، سعی در تعیین مرزهای تصمیمگیری برای جدا کردن کلاسها دارد.
6. کاربردها
رگرسیون: معمولاً در مواردی مانند پیشبینی قیمت، تحلیل روندها، و شبیهسازیهای عددی استفاده میشود.
طبقهبندی: معمولاً در مواردی مانند تشخیص تقلب، تشخیص بیماری، و دستهبندی متن به کار میرود.
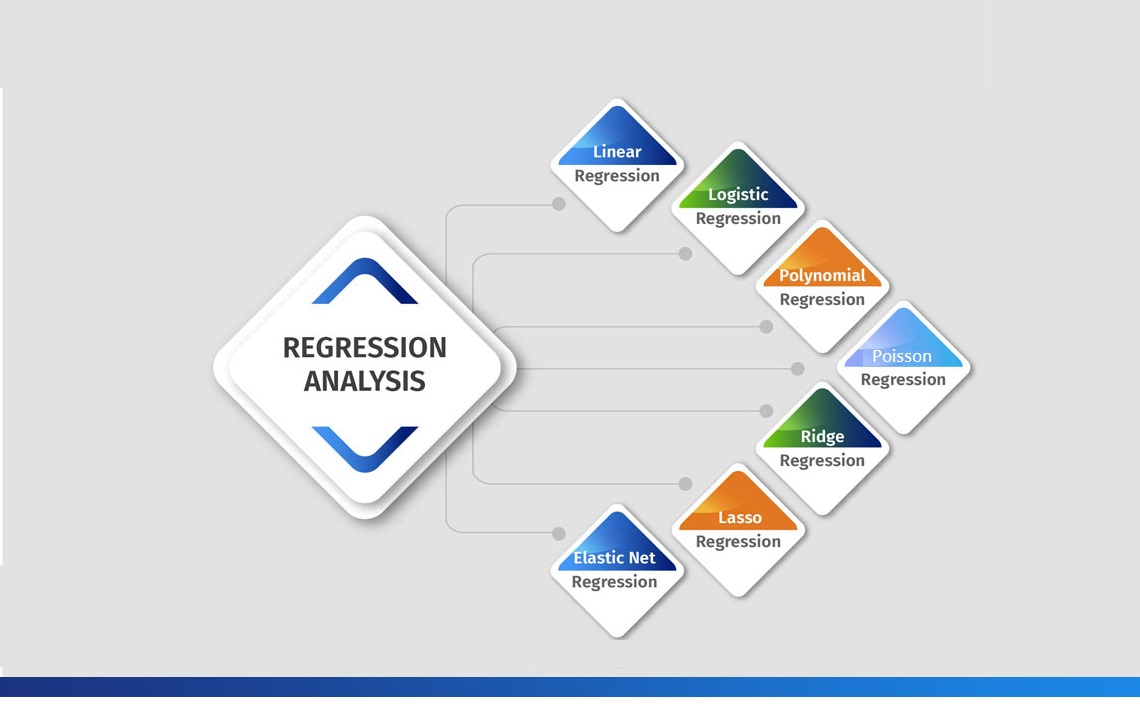
انواع تکنیک های رگرسیون در یادگیری ماشین
تکنیکهای رگرسیون در یادگیری ماشین به منظور پیشبینی مقادیر عددی از دادههای ورودی استفاده میشوند. در ادامه، به انواع مختلف تکنیکهای رگرسیون و ویژگیهای هر یک پرداخته میشود.
1. رگرسیون خطی (Linear Regression)
رگرسیون خطی ساده: شامل یک متغیر مستقل و یک متغیر وابسته است و هدف آن یافتن یک خط مستقیم است که بهترین برازش را به دادهها داشته باشد.
رگرسیون خطی چندگانه: شامل چندین متغیر مستقل برای پیشبینی یک متغیر وابسته است.
2. رگرسیون لجستیک (Logistic Regression)
هرچند این روش بیشتر برای طبقهبندی استفاده میشود، اما میتواند برای پیشبینی احتمال وقوع یک رویداد بکار رود. خروجی مدل یک احتمال بین 0 و 1 است که با تابع لجستیک محاسبه میشود.
3. رگرسیون پلینومیک (Polynomial Regression)
برای مدلسازی روابط غیرخطی بین متغیرها استفاده میشود
رگرسیون پلینومیک میتواند روابط پیچیدهتر را بهتر مدلسازی کند.
4. رگرسیون ریدج (Ridge Regression)
یک تکنیک رگرسیون خطی است که از منظمسازی (Regularization) برای جلوگیری از بیشبرازش (Overfitting) استفاده میکند. در این روش، یک جریمه به تابع هزینه افزوده میشود که اندازه ضرایب را محدود میکند.
5. رگرسیون لاسو (Lasso Regression)
مشابه رگرسیون ریدج است، اما در اینجا از جریمه L1 استفاده میشود که منجر به کاهش برخی از ضرایب به صفر میشود و در نتیجه انتخاب ویژگیها را نیز انجام میدهد.
6. رگرسیون Elastic Net
ترکیبی از رگرسیون ریدج و لاسو است و از هر دو نوع جریمه L1 و L2 استفاده میکند. این تکنیک برای دادههایی که شامل همخطی (Multicollinearity) هستند، بسیار مفید است.
7. رگرسیون درخت تصمیم (Decision Tree Regression)
از درختهای تصمیم برای مدلسازی روابط پیچیده استفاده میشود. در این تکنیک، دادهها به دستههای مختلف تقسیم میشوند و برای هر دسته، پیشبینی انجام میشود.
8. رگرسیون با استفاده از شبکههای عصبی (Neural Network Regression)
شبکههای عصبی میتوانند به عنوان مدلهای رگرسیونی برای یادگیری روابط غیرخطی و پیچیده بین متغیرها استفاده شوند. این مدلها با استفاده از لایههای مختلف از نورونها، میتوانند به طور مؤثری پیشبینی کنند.
9. رگرسیون محلی (Local Regression)
تکنیکهایی مانند LOESS (Locally Estimated Scatterplot Smoothing) از این روش استفاده میکنند. این روش برای پیشبینی مقدار خروجی در یک نقطه خاص بر اساس نقاط نزدیک به آن نقطه به کار میرود.
10. رگرسیون گامبهگام (Stepwise Regression)
یک تکنیک برای انتخاب ویژگیها است که بهطور خودکار متغیرهای مناسب را به مدل اضافه یا از آن حذف میکند. این روش میتواند به شناسایی بهترین مدل رگرسیون کمک کند.
خدمات اس دیتا
خدمات اس دیتا در زمینه تکنیکهای رگرسیون در یادگیری ماشین شامل طیف گستردهای از تحلیلها و مشاورههاست که به کسبوکارها کمک میکند تا از دادههای خود بهترین بهره را ببرند. این خدمات به شرح زیر هستند:
1. مشاوره و تحلیل داده
تحلیل نیازها: شناسایی نیازهای خاص کسبوکار و تعیین اهداف پیشبینی.
تحلیل دادهها: بررسی دادههای موجود و شناسایی روابط بین متغیرها.
2. پیادهسازی مدلهای رگرسیون
مدلسازی رگرسیون: طراحی و پیادهسازی مدلهای مختلف رگرسیون (خطی، پلینومیک، ریدج، لاسو و ...) بر اساس نیازهای خاص کسبوکار.
بهینهسازی مدل: تنظیم پارامترها و بهینهسازی مدل برای دستیابی به بهترین عملکرد.
3. آموزش و توانمندسازی
آموزش در زمینه تکنیکهای رگرسیون: ارائه کارگاهها و دورههای آموزشی برای تیمهای داخلی کسبوکارها به منظور آشنایی با تکنیکهای مختلف رگرسیون و نحوه پیادهسازی آنها.
آموزش ابزارها: آموزش استفاده از ابزارها و نرمافزارهای مرتبط با رگرسیون مانند Python، R، و ابزارهای BI.
4. تحلیل نتایج و گزارشدهی
تحلیل نتایج: بررسی و تحلیل نتایج پیشبینیها و ارائه بینشهای کلیدی به مدیران و ذینفعان.
گزارشدهی: ارائه گزارشهای جامع و بصری از نتایج و عملکرد مدلها.
5. انتخاب ویژگیها و کاهش ابعاد
انتخاب ویژگی: استفاده از تکنیکهای مختلف برای شناسایی و انتخاب ویژگیهای مؤثر در مدلسازی.
کاهش ابعاد: پیادهسازی روشهایی مانند PCA (تحلیل مؤلفههای اصلی) برای کاهش ابعاد دادهها و بهبود عملکرد مدلها.
6. بهروز رسانی و نگهداری مدلها
نگهداری مدلها: نظارت بر عملکرد مدلها و انجام بهروزرسانیهای لازم در صورت تغییر در دادهها یا شرایط بازار.
تست و ارزیابی: انجام ارزیابیهای دورهای برای اطمینان از دقت و کارایی مدلها.
7. تحلیل سناریو و شبیهسازی
تحلیل سناریو: شبیهسازی سناریوهای مختلف برای بررسی تأثیر تغییرات متغیرها بر پیشبینیها.
مدلسازی پیشبینی: ایجاد مدلهای پیشبینی برای ارزیابی تاثیرات تصمیمات تجاری مختلف.
8. یکپارچهسازی با سیستمهای موجود
یکپارچهسازی: ادغام مدلهای رگرسیون با سیستمهای موجود کسبوکار برای دستیابی به یک راهکار جامع و مؤثر.
9. خدمات سفارشیسازی
سفارشیسازی مدلها: ارائه خدمات سفارشی برای برآورده کردن نیازهای خاص کسبوکارها و ایجاد مدلهای مناسب بر اساس دادهها و ویژگیهای خاص آنها.



