
در این مقاله ما به بررسی روشها و معیارهای ارزیابی عملکرد الگوریتمهای یادگیری نظارتشده بر هوش مصنوعی در آمار میپردازیم. با تحلیل معیارهایی مانند دقت، حساسیت، ویژگی و امتیاز F1، ابزارهای قدرتمندی برای انتخاب بهترین مدلها و بهبود عملکرد سیستمها معرفی میشود.
معیارهای ارزیابی الگوریتمهای یادگیری نظارتشده در هوش مصنوعی
در دنیای هوش مصنوعی و یادگیری ماشین، معیارهای ارزیابی ابزارهایی هستند که برای تحلیل عملکرد الگوریتمها و مدلها استفاده میشوند. این معیارها به توسعهدهندگان کمک میکنند تا مشخص کنند که آیا یک مدل به درستی وظایف خود را انجام میدهد یا خیر. هر یک از این معیارها کاربردها و نقاط قوت خود را دارد و در شرایط خاصی به کار میآید.
1. دقت (Accuracy)
دقت یکی از سادهترین و پرکاربردترین معیارهای ارزیابی است. این معیار نشان میدهد چه درصدی از پیشبینیهای مدل درست بوده است.
مثال:
فرض کنید در یک مدل پیشبینی بیماری، از 1000 نمونه، 850 مورد به درستی پیشبینی شدهاند. دقت این مدل 85 درصد است.
اما دقت ممکن است در مجموعه دادههایی با توزیع نامتعادل گمراهکننده باشد. بهعنوان مثال، اگر 90 درصد نمونهها به یک کلاس خاص تعلق داشته باشند، مدلی که همیشه همان کلاس را پیشبینی کند نیز دقت بالایی خواهد داشت، حتی اگر عملکرد واقعی مدل ضعیف باشد.
2. حساسیت (Recall) یا نرخ بازیابی
حساسیت به ما میگوید مدل چقدر توانسته نمونههای مثبت واقعی را شناسایی کند. این معیار برای موقعیتهایی که شناسایی موارد مثبت اهمیت بالایی دارد، مانند پزشکی یا امنیت سایبری، بسیار مهم است.
مثال:
در یک مدل تشخیص سرطان:
- از 200 بیمار سرطانی واقعی، مدل توانسته 180 نفر را شناسایی کند.
حساسیت این مدل 90 درصد است.
این به این معناست که مدل توانسته بیشتر بیماران را شناسایی کند، اما هنوز 10 درصد از بیماران را از دست داده است، که میتواند در عمل بسیار خطرناک باشد.
3. ویژگی (Specificity)
ویژگی نشان میدهد که مدل چقدر خوب توانسته نمونههای منفی واقعی را شناسایی کند. این معیار زمانی اهمیت دارد که خطای پیشبینی مثبت کاذب (False Positive) مشکلساز باشد.
مثال:
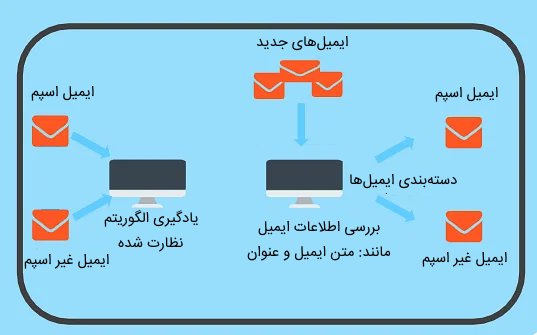
در یک مدل شناسایی اسپم:
- از 800 ایمیل غیر اسپم، مدل توانسته 760 ایمیل را درست شناسایی کند.
ویژگی این مدل 95 درصد است.
این به این معناست که مدل در جلوگیری از اشتباه برچسب زدن ایمیلهای غیر اسپم بهعنوان اسپم عملکرد خوبی دارد.
4. امتیاز F1 (F1-Score)
امتیاز F1 ترکیبی از دقت و حساسیت است و عملکرد مدل را زمانی که با دادههای نامتعادل مواجه هستیم، بهتر نشان میدهد.
این معیار نشان میدهد که مدل چقدر میتواند بین پیشبینیهای درست و اشتباه تعادل برقرار کند.
مثال:
فرض کنید مدلی برای تشخیص تقلب مالی توسعه داده شده است:
- دقت مدل 80 درصد و حساسیت آن 70 درصد است.
امتیاز F1 این مدل ترکیبی از این دو معیار است و نشان میدهد که مدل در پیشبینی درست موارد تقلب و کاهش خطاها عملکرد متعادلی دارد.
5. منحنی ROC و AUC
منحنی ROC (Receiver Operating Characteristic) و مساحت زیر منحنی (AUC) ابزارهایی گرافیکی برای مقایسه عملکرد مدلها هستند.
این معیارها نشان میدهند که مدل چقدر خوب میتواند کلاسهای مختلف را از هم تفکیک کند.
مثال:
دو مدل A و B برای پیشبینی کلاهبرداری تست شدهاند:
- مدل A دارای AUC برابر 0.92 است.
- مدل B دارای AUC برابر 0.85 است.
مدل A عملکرد بهتری دارد زیرا قدرت بیشتری در تمایز بین تراکنشهای کلاهبرداری و غیرکلاهبرداری دارد.
6. خطای میانگین مطلق (MAE) و خطای جذر میانگین مربعات (RMSE)
این معیارها برای مدلهای رگرسیون استفاده میشوند و میزان انحراف پیشبینیها از مقادیر واقعی را نشان میدهند.
- MAE خطای میانگین مطلق را اندازه میگیرد.
- RMSE انحرافات بزرگتر را بیشتر جریمه میکند.
مثال:
یک مدل قیمتگذاری املاک، قیمت 100 خانه را پیشبینی کرده است. اگر خطای میانگین مطلق مدل 10 هزار دلار و RMSE آن 15 هزار دلار باشد، نشان میدهد که مدل در برخی موارد خطاهای بزرگی داشته است.
7. ارزیابی مدل با دادههای نامتعادل
در بسیاری از کاربردها، دادهها به طور متعادل بین کلاسها توزیع نشدهاند. بهعنوان مثال:
- در یک مجموعه داده شامل 10,000 نمونه تراکنش بانکی، تنها 100 مورد تقلب هستند.
در چنین شرایطی، معیارهایی مانند دقت ممکن است مناسب نباشند و باید از معیارهایی مانند حساسیت، ویژگی، و F1-Score استفاده شود.
یک مثال عملی
فرض کنید یک مدل برای تشخیص تقلب در تراکنشهای بانکی توسعه داده شده است:
- تعداد کل تراکنشها: 10,000
- تراکنشهای تقلبی واقعی: 500
- پیشبینی مدل:
- تراکنشهای تقلبی درست شناساییشده: 450
- تراکنشهای غیرتقلبی درست شناساییشده: 9,300
- تراکنشهای تقلبی اشتباه شناساییشده: 50
- تراکنشهای غیرتقلبی اشتباه شناساییشده: 200
ارزیابی:
- دقت: 97.5 درصد (عملکرد کلی خوب است، اما حساسیت مهمتر است).
- حساسیت: 90 درصد (مدل بیشتر تقلبها را شناسایی کرده، اما هنوز 10 درصد را از دست داده است).
- ویژگی: 99.5 درصد (مدل توانسته بیشتر تراکنشهای عادی را به درستی شناسایی کند).
- F1-Score: ترکیب متعادلی از دقت و حساسیت.
کاربردهای عملی معیارهای ارزیابی در هوش مصنوعی
معیارهای ارزیابی در هوش مصنوعی بهطور گستردهای برای تحلیل و بهینهسازی عملکرد مدلها در مسائل مختلف استفاده میشوند. این معیارها نه تنها به پژوهشگران کمک میکنند تا مدلهای خود را بهبود دهند، بلکه در تصمیمگیریهای عملی و تجاری نیز نقش حیاتی دارند. در ادامه به برخی از کاربردهای عملی این معیارها در حوزههای مختلف اشاره شده است:
1. پزشکی و سلامت
در کاربردهایی مانند تشخیص بیماریها یا پیشبینی نتایج درمان، معیارهای ارزیابی بهطور مستقیم بر زندگی انسانها تأثیر میگذارند.
- حساسیت (Recall): در تشخیص بیماریهای جدی مانند سرطان، حساسیت بالا ضروری است تا بیماران مبتلا از قلم نیفتند.
- ویژگی (Specificity): در آزمایشهای غربالگری، ویژگی بالا اهمیت دارد تا موارد مثبت کاذب کاهش یابد و بیماران سالم نگرانی غیرضروری پیدا نکنند.
مثال:
یک سیستم تشخیص سرطان پوست:
- حساسیت 95 درصد (تشخیص بیشتر بیماران سرطانی).
- ویژگی 90 درصد (کاهش تشخیص اشتباه افراد سالم).
این ترکیب تضمین میکند که هم بیماران شناسایی شوند و هم از نگرانیهای غیرضروری جلوگیری شود.
2. امنیت سایبری
در سیستمهای تشخیص نفوذ (Intrusion Detection Systems) و شناسایی حملات سایبری:
- حساسیت: شناسایی تمام حملات واقعی اهمیت زیادی دارد، زیرا از دست دادن حتی یک حمله میتواند خسارتهای سنگینی به همراه داشته باشد.
- ویژگی: برای جلوگیری از هشدارهای کاذب، ویژگی بالا ضروری است، تا منابع و زمان صرف موارد غیرضروری نشود.
مثال:
یک سیستم تشخیص حملات سایبری که 98 درصد حساسیت و 85 درصد ویژگی دارد، میتواند بیشتر حملات واقعی را شناسایی کرده و تعداد هشدارهای کاذب را کاهش دهد.
3. بانکداری و امور مالی
در مسائل مربوط به تشخیص تقلب یا پیشبینی ریسک مالی:
- امتیاز F1: در مجموعه دادههای نامتعادل، این معیار نشاندهنده تعادل بین شناسایی تقلب و جلوگیری از هشدارهای کاذب است.
- AUC (مساحت زیر منحنی ROC): برای ارزیابی قدرت مدل در تفکیک تراکنشهای تقلبی از عادی.
مثال:
یک مدل تشخیص تقلب در بانک با دادههای زیر:
- 10,000 تراکنش، 100 مورد تقلب واقعی.
- مدل توانسته 90 مورد تقلب را شناسایی کند، اما 50 هشدار اشتباه داده است.
مدل با F1-Score بالا عملکرد خوبی در شناسایی موارد مهم و کاهش خطاهای کاذب دارد.
4. تجارت الکترونیک و بازاریابی
در سیستمهای پیشنهاددهنده، معیارهای ارزیابی برای بهبود تجربه کاربر و افزایش فروش اهمیت دارند:
- دقت (Precision): نشان میدهد که پیشنهادها چقدر مرتبط هستند.
- حساسیت (Recall): تعداد مواردی که میتوانست پیشنهاد شود و شناسایی شده است.
مثال:
در یک فروشگاه آنلاین، سیستمی که با دقت 80 درصد و حساسیت 70 درصد پیشنهادهایی ارائه میدهد، میتواند مشتری را به خرید محصولات مرتبطتر ترغیب کند، در حالی که درصد کمتری از موارد نامربوط را نشان میدهد.
5. حملونقل و خودروهای خودران
در سیستمهای دید کامپیوتری خودروهای خودران:
- حساسیت: شناسایی عابرین پیاده، خودروها و موانع برای جلوگیری از تصادف.
- ویژگی: اجتناب از هشدارهای نادرست، تا تصمیمگیری خودرو بهینه باشد.
مثال:
یک سیستم تشخیص موانع که 99 درصد حساسیت دارد، میتواند تقریباً تمام موانع را شناسایی کند، اما اگر ویژگی آن پایین باشد، ممکن است به اشتباه موانع غیرواقعی را تشخیص دهد، که باعث توقفهای غیرضروری میشود.
6. تولید محتوا و پردازش زبان طبیعی (NLP)
در کاربردهایی مانند ترجمه ماشینی، چتباتها و خلاصهسازی متون:
- BLEU Score: برای ارزیابی کیفیت ترجمه.
- ROUGE Score: برای ارزیابی کیفیت خلاصهسازی متون.
مثال:
یک مدل ترجمه ماشینی با BLEU Score برابر با 75 درصد نشان میدهد که ترجمههای آن به میزان قابلتوجهی با ترجمه انسانی مشابه هستند و کیفیت بالایی دارند.
7. صنعت و تولید
در سیستمهای نگهداری و تعمیر پیشبینانه (Predictive Maintenance):
- دقت: برای پیشبینی خرابیها.
- حساسیت: برای جلوگیری از خرابیهای بزرگ، حساسیت بالا ضروری است تا بیشتر خرابیهای احتمالی پیشبینی شوند.
مثال:
یک سیستم پیشبینی خرابی دستگاهها با دقت 90 درصد و حساسیت 95 درصد میتواند هزینههای تعمیرات ناگهانی را کاهش داده و از توقف تولید جلوگیری کند.
8. آموزش و تحلیل رفتار کاربران
در سیستمهای آموزشی آنلاین یا تحلیل رفتار کاربران در اپلیکیشنها:
- دقت: نشاندهنده میزان صحیح بودن پیشبینیها در مورد عملکرد یا نیاز کاربران است.
- حساسیت و ویژگی: برای شناسایی دقیق نیازهای کاربران یا رفتارهای غیرعادی.
مثال:
یک سیستم پیشبینی موفقیت دانشجویان در آزمونها با حساسیت 85 درصد میتواند اکثر دانشجویانی که به کمک نیاز دارند را شناسایی کند.
نتیجهگیری
معیارهای ارزیابی در هوش مصنوعی ابزارهایی ضروری برای تحلیل و بهبود مدلها هستند. استفاده از معیارهای مناسب بستگی به نوع مسئله و اهمیت پیشبینیهای درست و اشتباه دارد. ترکیب چندین معیار میتواند تصویر دقیقتری از عملکرد مدل ارائه دهد و به بهینهسازی آن کمک کند.



