
آمار توصیفی یکی از ابزارهای ضروری در تحلیل دادهها و آمادهسازی آنها برای یادگیری ماشین است. این تکنیکها به پژوهشگران و متخصصان کمک میکنند تا با درک دقیق توزیع دادهها، روندها و روابط میان متغیرها، مدلهای یادگیری ماشین را با دقت و کارایی بیشتری طراحی کنند.
در واقع، هوش مصنوعی در آمار از این روشها برای بهبود فرایند پیشبینی و تصمیمگیری بهره میبرد. استفاده از آمار توصیفی پایهای قوی برای توسعه مدلهای پیشرفته هوش مصنوعی فراهم میکند و نقش مهمی در موفقیت پروژههای دادهمحور ایفا میکند.
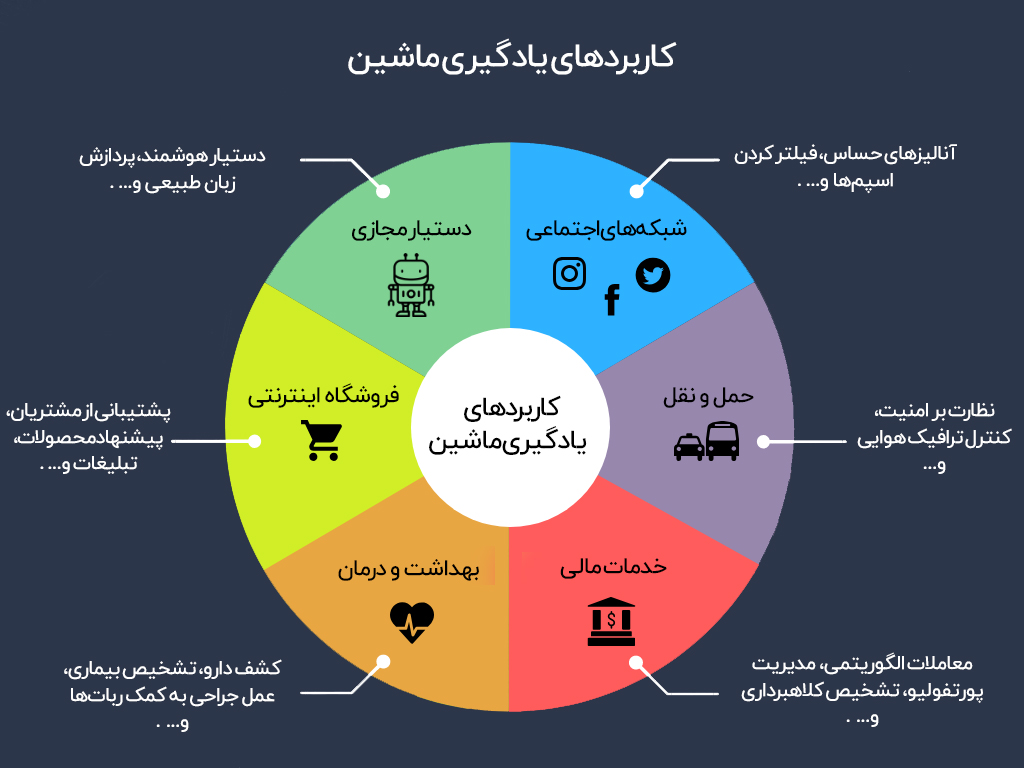
تحلیل دادهها با آمار توصیفی در یادگیری ماشین
آمار توصیفی در طراحی مدلهای یادگیری ماشین یکی از مراحل اساسی برای آمادهسازی دادهها و درک بهتر آنهاست. هدف اصلی آمار توصیفی، خلاصهسازی و توصیف ویژگیهای کلیدی مجموعه دادهها به گونهای است که الگوها و روابط موجود در آن آشکار شوند. این مرحله به دانشمندان داده کمک میکند تا کیفیت دادهها را ارزیابی کرده و تصمیمات بهتری برای طراحی مدلها بگیرند.
مثال: تحلیل دادهها برای پیشبینی قیمت خانه
فرض کنید دادههایی شامل متغیرهای "متراژ"، "تعداد اتاقها"، "سن ساختمان" و "قیمت نهایی" داریم. پیش از طراحی مدل یادگیری ماشین، باید این دادهها را تحلیل کنیم:
-
میانگین و میانه
میانگین قیمت خانهها 750 میلیون تومان و میانه آن 700 میلیون تومان است. این اختلاف نشان میدهد برخی دادهها (خانههای بسیار گران یا ارزان) ممکن است تأثیر قابلتوجهی بر میانگین داشته باشند. -
انحراف معیار و پراکندگی دادهها
انحراف معیار قیمتها 120 میلیون تومان است، به این معنا که بیشتر قیمتها در محدوده 630 تا 870 میلیون تومان قرار دارند. آمار توصیفی در طراحی مدلهای یادگیری ماشین به ما کمک میکند تا بفهمیم آیا دادهها به صورت یکنواخت توزیع شدهاند یا خیر. -
بررسی توزیع دادهها
با استفاده از هیستوگرام، متوجه میشویم که توزیع قیمتها به سمت بالا متمایل است (چولگی مثبت). این نکته اهمیت دارد، زیرا ممکن است نیاز به تبدیل متغیر قیمت برای بهتر شدن عملکرد مدل داشته باشیم.
اهمیت آمار توصیفی در طراحی مدلهای یادگیری ماشین
- شناسایی دادههای پرت: مثلاً خانهای با قیمت 5 میلیارد تومان در این مجموعه داده، به وضوح یک داده پرت است. حذف یا مدیریت این دادهها برای جلوگیری از تاثیر منفی آنها بر مدل ضروری است.
- تشخیص روابط اولیه بین متغیرها: بررسی همبستگی بین متراژ و قیمت نشان میدهد که ضریب همبستگی آنها 0.85 است، یعنی رابطه قوی و مستقیم دارند.
- آمادهسازی برای انتخاب ویژگیها: اگر متغیری مثل "کد منطقه" هیچ ارتباط معناداری با قیمت نداشته باشد، میتوان آن را در مراحل اولیه حذف کرد.
مزایای آمار توصیفی در یادگیری ماشین
- صرفهجویی در زمان: با بررسی دقیق دادهها، از تلاشهای بینتیجه برای مدلسازی دادههای کمکیفیت جلوگیری میشود.
- افزایش دقت مدل: با شناخت بهتر دادهها، میتوان متغیرهای مناسبتر را انتخاب کرد و مدلهایی با دقت بالاتر طراحی کرد.
- مدیریت ناهنجاریها: تحلیل دادههای پرت یا ناهماهنگ به بهبود نتایج نهایی کمک میکند.
چطور آمار توصیفی در پیشبینیهای مدلهای یادگیری ماشین تاثیر میگذارد؟
آمار توصیفی در طراحی مدلهای یادگیری ماشین نقش حیاتی در افزایش دقت و کارایی پیشبینیها ایفا میکند. این روشها با خلاصهسازی و تحلیل دادهها، کیفیت ورودیها را برای مدل تضمین کرده و پایهای قوی برای پردازشهای پیچیدهتر فراهم میکنند. در ادامه، تاثیر آمار توصیفی بر پیشبینیهای مدلهای یادگیری ماشین را بررسی میکنیم.
1. شناسایی و حذف دادههای پرت
دادههای پرت میتوانند عملکرد مدل را به شدت کاهش دهند. برای مثال، در مجموعه دادهای مربوط به پیشبینی قیمت خودرو، اگر خودرویی با قیمتی بسیار بالاتر یا پایینتر از سایر دادهها وجود داشته باشد، ممکن است مدل را به سمت نتایج غیرواقعی هدایت کند. با استفاده از آماری مانند چارکها یا دامنه بین چارکی (IQR) میتوان این دادهها را شناسایی و مدیریت کرد.
2. بهبود توزیع دادهها
آمار توصیفی، اطلاعات ارزشمندی درباره توزیع دادهها ارائه میدهد. برای مثال:
- اگر متغیر هدف (مانند قیمت یا فروش) چولگی زیادی داشته باشد، ممکن است نیاز به استفاده از تبدیلات لگاریتمی یا ریشهای برای متعادل کردن توزیع دادهها باشد.
- توزیع نرمال دادهها به مدلهای یادگیری ماشین مانند رگرسیون خطی کمک میکند تا عملکرد بهتری داشته باشند.
3. انتخاب و تحلیل ویژگیها
آمار توصیفی در طراحی مدلهای یادگیری ماشین به شناسایی متغیرهای کلیدی کمک میکند. برای مثال:
- با محاسبه ضریب همبستگی، میتوان فهمید که کدام متغیرها تأثیر بیشتری بر پیشبینی دارند. اگر در یک مدل پیشبینی قیمت خانه، ضریب همبستگی بین "متراژ" و "قیمت" 0.9 باشد، میتوان این متغیر را به عنوان یکی از مهمترین عوامل در نظر گرفت.
- متغیرهایی با همبستگی پایینتر یا بدون تأثیر میتوانند حذف شوند تا مدل سادهتر و سریعتر اجرا شود.
4. ارزیابی پراکندگی و واریانس دادهها
مدلهای یادگیری ماشین مانند درخت تصمیم یا شبکههای عصبی به توزیع مناسب دادهها وابسته هستند. برای مثال:
- اگر واریانس یک متغیر بسیار کم باشد (مانند متغیری که تقریباً برای تمام دادهها مقدار ثابتی دارد)، آن متغیر اطلاعات مفیدی برای پیشبینی فراهم نمیکند و میتوان آن را حذف کرد.
- با تحلیل آماری مانند انحراف معیار و واریانس، میتوان چنین متغیرهایی را شناسایی کرد.
5. تسریع فرایند یادگیری مدل
آمار توصیفی در طراحی مدلهای یادگیری ماشین، به بهینهسازی دادهها و حذف نویزهای غیرضروری کمک میکند. این فرایند به مدل اجازه میدهد تا سریعتر آموزش ببیند و پیشبینیهایی با دقت بالاتر ارائه کند. برای مثال:
- استانداردسازی و نرمالسازی دادهها (محاسبه میانگین و انحراف معیار) از طریق آمار توصیفی باعث میشود مدلهایی مانند ماشینهای بردار پشتیبان (SVM) یا شبکههای عصبی بهتر عمل کنند.
6. بهبود ارزیابی عملکرد مدل
پیش از آموزش مدل، آمار توصیفی میتواند برای ارزیابی کیفیت دادههای آموزشی استفاده شود. برای مثال:
- اگر توزیع دادهها به شدت نامتوازن باشد (مانند 90 درصد از دادهها در یک کلاس و 10 درصد در کلاس دیگر)، مدل ممکن است دچار سوگیری شود. با تحلیل دادهها و استفاده از روشهایی مانند نمونهگیری مجدد یا وزندهی کلاسها، میتوان این مشکل را برطرف کرد.
مثال عملی: پیشبینی فروش یک فروشگاه آنلاین
فرض کنید دادههایی شامل متغیرهایی مثل تعداد بازدیدهای روزانه، نرخ تبدیل، تخفیفها و فروش روزانه دارید.
- با محاسبه میانگین فروش (50 هزار تومان) و انحراف معیار (10 هزار تومان)، متوجه میشوید که فروش روزانه عموماً در محدوده 40 تا 60 هزار تومان قرار دارد.
- بررسی همبستگی نشان میدهد که تخفیفها تأثیر مثبت 0.7 بر فروش دارند، اما نرخ تبدیل تأثیر ضعیفی دارد (0.2).
- دادههای پرت مربوط به روزهای خاص (مانند حراجهای بزرگ) شناسایی و جدا میشوند تا نتایج بهتری حاصل شود.
نتیجهگیری
آمار توصیفی یکی از بخشهای حیاتی در فرآیند پیشبینی با یادگیری ماشین است. این روشها با تحلیل دقیق دادهها، شناسایی مشکلات و بهبود کیفیت ورودیها، دقت و قابلیت اعتماد مدلها را افزایش میدهند.
آمار توصیفی در طراحی مدلهای یادگیری ماشین به پژوهشگران این امکان را میدهد که مدلهایی دقیقتر، سریعتر و موثرتر بسازند و نتایجی قابل اعتماد ارائه دهند.



