
تحلیل خوشه بندی داده ها یکی از روش های کلیدی برای شناسایی الگو ها و تقسیم بندی داده ها است. با ترکیب روش های آماری مانند تحلیل واریانس و فاصله اقلیدسی با الگوریتم های هوش مصنوعی مانند K-Means و DBSCAN، میتوان خوشه بندی های دقیق تری انجام داد.
هوش مصنوعی در آمار به بهبود عملکرد این روش ها کمک می کند و امکان تحلیل داده های پیچیده و بزرگ را فراهم می سازد. این ترکیب به سازمان ها کمک می کند تا تصمیم گیری های مبتنی بر داده بهتری داشته باشند و گروه های پنهان در داده ها را به خوبی شناسایی کنند.
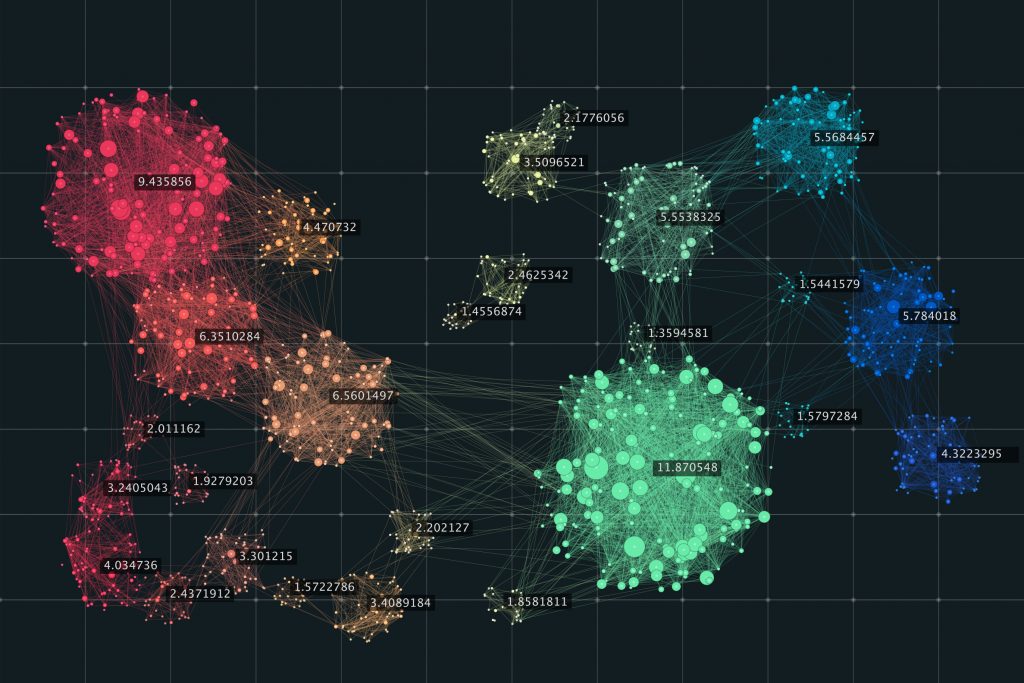
خوشه بندی داده ها: ترکیب قدرت آمار و هوش مصنوعی
خوشه بندی داده ها یکی از تکنیک های کلیدی در علم داده است که به شناسایی گروه ها یا خوشه های پنهان در داده ها کمک می کند. این روش در یادگیری ماشین بدون نظارت (Unsupervised Learning) به کار می رود و زمانی که داده ها بدون برچسب یا طبقه باشند، بسیار مفید است. ترکیب آمار و هوش مصنوعی در خوشه بندی داده ها، رویکردی قوی برای تحلیل داده های پیچیده، بزرگ، و نامتقارن ارائه می دهد. آمار با ارائه ابزار های دقیق برای اندازه گیری و ارزیابی شباهت ها و تفاوت ها، و هوش مصنوعی با الگوریتم های قدرتمند و مقیاس پذیر، نتایج دقیق تر و موثرتری را ممکن می سازند.
آمار در خوشه بندی داده ها
آمار ابزار های متعددی برای تحلیل داده ها در خوشه بندی فراهم می کند. این ابزار ها شامل اندازه گیری هایی مانند فاصله (مانند فاصله اقلیدسی)، میانگین و واریانس برای هر خوشه، و تحلیل واریانس (ANOVA) برای ارزیابی تفاوت بین خوشه ها هستند.
- فاصله: محاسبه شباهت بین داده ها
- میانگین و واریانس: بررسی پراکندگی و مرکزیت هر خوشه
- تحلیل واریانس: اطمینان از اینکه خوشه ها به طور معنی داری از یکدیگر متفاوت هستند.
مثال آماری:
فرض کنید داده های فروش محصولات یک فروشگاه شامل قیمت، تعداد فروش و تعداد بازدید مشتریان است. با استفاده از آمار:
- میانگین قیمت محصولات در خوشه 1: 50دلار50 دلار
- میانگین قیمت محصولات در خوشه 2: 150دلار150 دلار
- تحلیل واریانس نشان می دهد که تفاوت بین خوشه ها از نظر قیمت و تعداد فروش معنی دار است، که بیانگر رفتار متفاوت مشتریان است.
هوش مصنوعی در خوشه بندی داده ها
هوش مصنوعی، الگوریتم های پیشرفته ای برای خوشه بندی داده ها ارائه می دهد که با داده های بزرگ و پیچیده سازگار هستند. روش هایی مانند K-Means، DBSCAN، و الگوریتم های سلسله مراتبی (Hierarchical Clustering) نمونه هایی از این الگوریتم ها هستند.
مزایای الگوریتم های هوش مصنوعی:
- سرعت بالا: الگوریتم هایی مانند K-Means می توانند داده های بزرگ را با سرعت بالا پردازش کنند.
- انعطاف پذیری: الگوریتم هایی مانند DBSCAN می توانند با داده های نویزی یا غیر نرمال کار کنند.
- قابلیت بصری سازی: نتایج الگوریتم ها می توانند به صورت بصری نمایش داده شوند، که به درک بهتر گروه بندی داده ها کمک می کند.
مثال هوش مصنوعی:
فرض کنید یک فروشگاه آنلاین می خواهد مشتریان خود را بر اساس رفتار خرید به سه خوشه تقسیم کند:
- خوشه 1: مشتریانی که خرید های کوچک اما مکرر انجام می دهند.
- خوشه 2: مشتریانی که خرید های بزرگ اما کم تکرار دارند.
- خوشه 3: مشتریانی که تنها یک بار خرید کرده اند.
با استفاده از الگوریتم K-Means، این خوشه ها به طور خودکار ایجاد می شوند.
ترکیب آمار و هوش مصنوعی در خوشه بندی
وقتی آمار و هوش مصنوعی با هم ترکیب شوند، قدرت تحلیل داده ها به میزان قابل توجهی افزایش می یابد. آمار به ما کمک می کند تا ساختار داده ها را بشناسیم، فاصله ها و پراکندگی را بررسی کنیم و مدل های خوشه بندی را ارزیابی کنیم. هوش مصنوعی با ارائه الگوریتم هایی که توانایی پردازش داده های بزرگ را دارند، نتایج خوشه بندی را بهینه می کند.
مراحل ترکیبی:
- تحلیل اولیه داده ها با آمار: بررسی پراکندگی و همبستگی داده ها، استفاده از تحلیل واریانس برای شناسایی تفاوت های اولیه.
- اجرای الگوریتم های هوش مصنوعی: استفاده از روش هایی مانند K-Means یا DBSCAN برای گروه بندی داده ها.
- ارزیابی نتایج خوشه بندی با آمار: محاسبه معیار هایی مانند میانگین فاصله ها در هر خوشه، ارزیابی واریانس خوشه ها.
مطالعه موردی: خوشه بندی مشتریان یک فروشگاه
یک فروشگاه می خواهد مشتریان خود را بر اساس رفتار خرید خوشه بندی کند. داده ها شامل متغیر هایی مانند تعداد خرید، میانگین مبلغ خرید، و دفعات مراجعه هستند.
داده ها:
- مشتری 1: [20خرید،50دلارمیانگین،10مراجعه][20 خرید، 50 دلار میانگین، 10 مراجعه]
- مشتری 2: [5خرید،200دلارمیانگین،2مراجعه][5 خرید، 200 دلار میانگین، 2 مراجعه]
- مشتری 3: [30خرید،40دلارمیانگین،15مراجعه][30 خرید، 40 دلار میانگین، 15 مراجعه]
- مشتری 4: [3خرید،300دلارمیانگین،1مراجعه][3 خرید، 300 دلار میانگین، 1 مراجعه]
روش ترکیبی:
با آمار:
- میانگین خرید: 14.514.5
- واریانس مبلغ خرید: 10,00010,000
- فاصله اقلیدسی بین مشتری 1 و مشتری 3: نزدیک است، بنابراین احتمالاً در یک خوشه قرار می گیرند.
با هوش مصنوعی:
- الگوریتم K-Means سه خوشه ایجاد می کند:
- خوشه 1: مشتریان با خرید زیاد و مبلغ کم (مانند مشتری 1 و مشتری 3).
- خوشه 2: مشتریانی که خرید کم و مبلغ بالا دارند (مانند مشتری 2 و مشتری 4).
نتایج:
- خوشه 1: میانگین مبلغ خرید 45دلار45 دلار
- خوشه 2: میانگین مبلغ خرید 250دلار250 دلار
مزایای ترکیب آمار و هوش مصنوعی در خوشه بندی
- دقت بالا: تحلیل آماری ساختار داده ها را بهتر مشخص می کند و الگوریتم های هوش مصنوعی خوشه بندی را با این تحلیل ها تقویت می کنند.
- مقیاس پذیری: ترکیب این دو روش امکان تحلیل داده های بزرگ را با دقت و سرعت بالا فراهم می کند.
- قابلیت تفسیر نتایج: نتایج خوشه بندی نه تنها دقیق تر هستند، بلکه قابل تفسیر و عملی نیز خواهند بود.
چگونه آمار و هوش مصنوعی گروه های پنهان در داده ها را شناسایی می کنند؟
یکی از بزرگ ترین چالش های تحلیل داده ها، شناسایی گروه های پنهان یا الگو های مخفی در میان حجم زیادی از داده هاست. این گروه ها معمولاً دارای ویژگی های مشترکی هستند که با نگاه اول قابل شناسایی نیستند. ترکیب آمار و هوش مصنوعی، روشی نوین برای کشف این الگو ها ارائه می دهد. آمار به درک ساختار داده ها، تعیین معیار های شباهت و تفاوت، و ارزیابی خوشه بندی کمک می کند، در حالی که هوش مصنوعی با قدرت پردازش بالا و الگوریتم های پیشرفته قادر است به طور خودکار این گروه های پنهان را شناسایی کند.
نقش آمار در شناسایی گروه های پنهان
آمار ابزار های دقیقی برای تحلیل الگو های موجود در داده ها و تفکیک گروه های مختلف فراهم می کند. این ابزار ها شامل موارد زیر هستند:
1. تحلیل همبستگی و وابستگی داده ها
آمار به ما کمک می کند تا روابط میان متغیر ها را شناسایی کنیم و متغیر های کلیدی در شناسایی گروه های پنهان را پیدا کنیم.
- مثال:
در تحلیل مشتریان یک فروشگاه، همبستگی بین تعداد خرید و مبلغ خرید نشان می دهد که مشتریانی که خرید بیشتری انجام می دهند معمولاً مبلغ بیشتری نیز خرج می کنند. این رابطه می تواند به شناسایی گروه های مشتریان وفادار کمک کند.
2. تحلیل چند متغیره (Multivariate Analysis)
این روش به بررسی تعامل همزمان چندین متغیر کمک می کند. به عنوان مثال، تحلیل مؤلفه های اصلی (PCA) به کاهش ابعاد داده و شناسایی الگو های پنهان در داده های پیچیده کمک می کند.
- مثال:
در تحلیل داده های مالی، از PCA می توان برای کاهش داده های مربوط به شاخص های متعدد (مانند درآمد، هزینه، و ریسک) استفاده کرد و گروه های پنهان سرمایه گذاران با رفتار مشابه را شناسایی کرد.
3. تحلیل پراکندگی و تراکم داده ها
آمار از ابزار هایی مانند نمودار پراکندگی و شاخص های تراکم برای شناسایی نقاط داده ای که رفتار مشابهی دارند استفاده می کند.
- مثال:
در تحلیل رفتار کاربران یک وب سایت، میتوان از تراکم بازدید ها در ساعات مختلف روز برای شناسایی الگوی فعالیت کاربران بهره برد.
نقش هوش مصنوعی در شناسایی گروه های پنهان
هوش مصنوعی با الگوریتم های یادگیری ماشین، به ویژه یادگیری بدون نظارت (Unsupervised Learning)، توانایی شناسایی گروه های پنهان را به طور خودکار دارد. این الگوریتم ها بر اساس الگو های آماری و روابط پیچیده میان داده ها عمل می کنند.
1. الگوریتم های خوشه بندی
الگوریتم هایی مانند K-Means، DBSCAN، و خوشه بندی سلسله مراتبی (Hierarchical Clustering) از مهم ترین ابزار های هوش مصنوعی برای شناسایی گروه های پنهان هستند.
- مثال:
در تحلیل داده های پزشکی، K-Means می تواند بیماران را بر اساس علائم مشترک به گروه هایی مانند بیماران با علائم خفیف، متوسط، و شدید تقسیم کند.
2. شبکه های عصبی خودسازمانده (Self-Organizing Maps)
این روش در شبکه های عصبی به طور خاص برای شناسایی الگو های پنهان در داده های پیچیده به کار می رود.
- مثال:
در تحلیل داده های تصویری، این روش می تواند تصاویری که ویژگی های مشترکی دارند را بدون نیاز به برچسب گذاری به خوشه های مختلف تقسیم کند.
3. تحلیل خوشه بندی عمیق (Deep Clustering)
این روش ترکیبی از یادگیری عمیق و خوشه بندی است که برای شناسایی گروه های پنهان در داده های بزرگ و پیچیده به کار می رود.
- مثال:
در سیستم های پیشنهاد دهنده فیلم ها و سریال ها، از تحلیل خوشه بندی عمیق برای شناسایی علایق پنهان کاربران استفاده می شود.
ترکیب آمار و هوش مصنوعی برای شناسایی گروه های پنهان
مرحله 1: تحلیل اولیه با آمار
- هدف: شناسایی ویژگی های کلیدی و تعیین روابط بین متغیر ها.
- ابزار: همبستگی، تحلیل پراکندگی، تحلیل واریانس.
- مثال: تحلیل داده های فروش نشان می دهد که مشتریانی که بیشتر از 10 بار خرید کرده اند، معمولاً در گروه مشتریان وفادار قرار می گیرند.
مرحله 2: اجرای الگوریتم های هوش مصنوعی
- هدف: گروه بندی داده ها به صورت خودکار بر اساس الگو های کشف شده.
- ابزار: K-Means، DBSCAN، شبکه های عصبی خودسازمانده.
- مثال: با استفاده از K-Means، داده ها به سه خوشه تقسیم می شوند:
- خوشه 1: مشتریان وفادار.
- خوشه 2: مشتریان جدید.
- خوشه 3: مشتریانی که فقط یک بار خرید کرده اند.
مرحله 3: ارزیابی خوشه ها با آمار
- هدف: ارزیابی دقت و معنی داری خوشه بندی.
- ابزار: شاخص هایی مانند میانگین فاصله داخل خوشه (Intra-Cluster Distance) و فاصله بین خوشه ها (Inter-Cluster Distance).
- مثال: اگر میانگین فاصله داخل خوشه 2 کوچکتر از 5 باشد و فاصله بین خوشه ها بزرگتر از 10 باشد، نشان می دهد که خوشه بندی دقیق و معنادار است.
نتیجه گیری
ترکیب آمار و هوش مصنوعی در خوشه بندی داده ها، رویکردی نوآورانه و موثر برای تحلیل داده ها ارائه می دهد. آمار با فراهم کردن ابزار های ارزیابی و درک بهتر داده ها، و هوش مصنوعی با الگوریتم های قدرتمند و مقیاس پذیر، این امکان را فراهم می کنند که خوشه بندی های دقیق و معنی دار انجام شود. این ترکیب در حوزه های مختلف مانند بازاریابی، پزشکی، و تحلیل داده های مالی بسیار ارزشمند است و می تواند تصمیم گیری های مبتنی بر داده را بهبود بخشد.



